
Motivations
Designing a real time networking protocol such as Unity’s NGO or the Photon Engine is certainly no easy feat, and it can take a certain level of misplaced confidence to think that one could top the robustness of battle-tested frameworks designed and developed by hundreds and perhaps thousands of network engineers over the course of decades. However, existing general purpose multiplayer networking frameworks were motivated by traditional desktop applications with remote authoritative server and/or relays in mind, for which bandwidth optimization is of the utmost importance and latency and jitter sit quite far back amongst all other priorities. In fact, considering that a latency of 100 ms is considered to be well under human perceptive threshold for non-instantaneity, modern server-authoritative models can easily meet such requirements even with added latency from interpolation buffering. So why would anyone want to reinvent the wheel?
We must first acknowledge that there is always an equivalent non-functional requirement on the desktop/mobile systems as there is on XR systems. One of the more unique parts of XR is being able to manipulate virtual objects in space through a controller or hand-tracking. Non-functional requirements for such a feature would be a moderately high-frequency controller pose update and subsequent network controller update to a server. In the desktop/mobile ecosystem, FPS games like Counter Strike require a constant stream of mouse movement deltas from the clients, which is non-functionally equivalent to XR network controller updates. Therefore, if the problem domain of desktop applications spans mostly the same domain as that of XR applications, we can simply use existing networking solutions and avoid unnecessary labor.
Yet, despite such similarities, XR calls for a higher standard in latency due to human visual perception. Take for example Figure 1, where we have a virtual grabbable object, a basketball, which responds to pose updates of its grabber. The diagram is drawn from the client’s perspective, and hence the grabber will appear instantaneous to the client since it will be updated through the controller API calls. The basketball’s position, however, will be updated only when the client receives a network update from the server. And for now, we will assume that we’ll do neither server nor client side predictions.
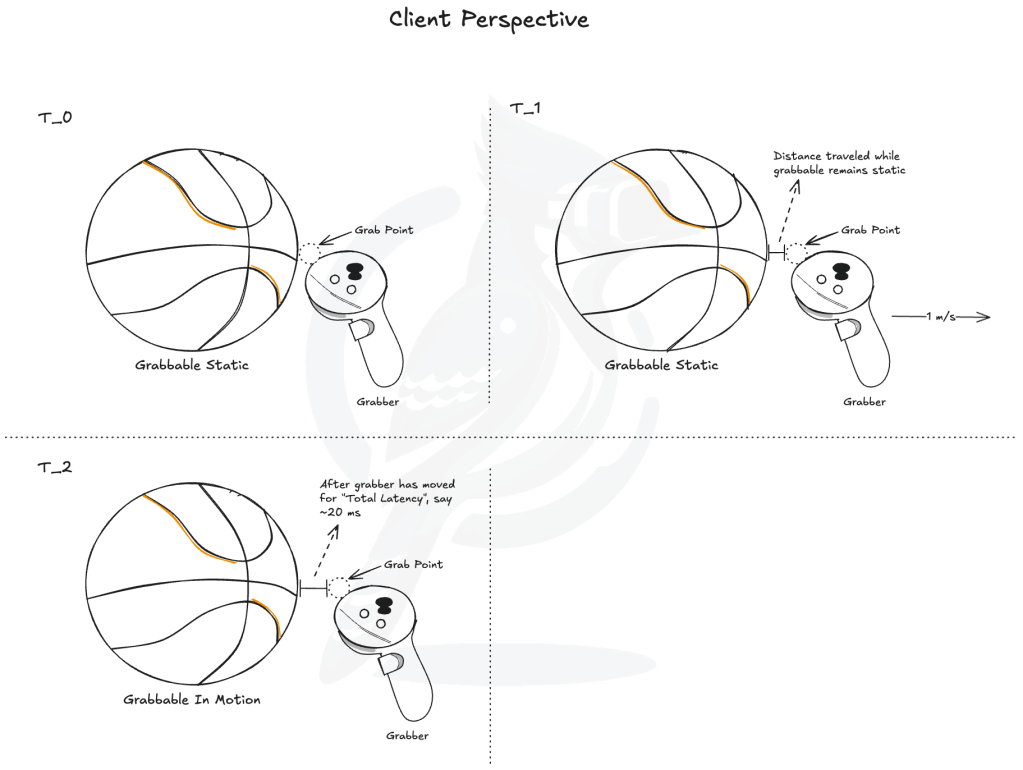
Figure 1.
Next, because the basketball’s pose is updated upon receiving the server’s network objects stream, the client’s observation of the basketball at any point in time is a state that happened strictly in the past by several milliseconds, and that is on average half a network echo round-trip time (RTT) considering wireless communication in local area network; that happens to be around 10 ms for the full RTT on modern 5/6/6E routers without QoS setting.
Let’s now assume that at time T0, the grabber has been sitting idly for a sufficiently long time for the basketball to appear static. In order for the client to see any change in the basketball’s pose as a result of the client’s physical actions, it must wait at least network echo RTT plus some processing time on the server’s end, the combination of which I don’t really have a good name for yet, so we’ll just call it “Total Latency”. Now let’s say that the client is moving the basketball at an even walking speed of 1 m/s. At some time between T0 and the first observation of the basketball moving, we have a time T1 when the grabber will have traveled an observable amount of distance while the basketball is still seemingly static. Then finally at time T2, the client will have gotten the very first frame from the server where the basketball is no longer at the same static pose and from that point onwards, the basketball will seem to move at 1 m/s towards the grabber maintaining the observable distance gap achieved from T0 to T2 through a time period that included T1. Assuming that on average the pipeline time is 20 ms, having traveled at 1 m/s for 20 ms yields a whopping 2 cm. Knowing that’s just at a walking speed, we can finally see why a naive implementation of the server authoritative model can be limiting for reflex based activities like table tennis.
This puts us at a unique crossroads: given the obvious limitations of a strictly server authoritative model for XR applications, should we even keep advocating it? Well to start in favor of server authority, it is conceptually very easy. At the core of the model, both the server and the client each send steady streams of information. The server sends regular updates of existing network objects’ transforms and perhaps some custom metadata. The client on the other hand sends updates of their controller and headset positions. Then, right on top of that we have the RPC layer, where both the client and the server can send one-off RPC to each other. A robust RPC layer would allow the clients to send controller inputs and the server to initiate audio and visual effects, thereby enabling frictionless bidirectional interactivity. With multiple clients, each client receives the same game state from the server, meaning clients can be synchronized amongst each other with no extra effort than initiating that first contact with the server, meaning fan-out to any number of clients is trivial bar the server performance and bandwidth costs.
Okay, but what about alternatives like P2P or client authoritative frameworks? In my very limited and narrow understanding of lockstep, P2P protocols like those used for fighting or RTS games, the base game engine is required to be deterministic, because each player must step through simulations based on each others’ inputs. It can be delay-based where a player must wait for the other player’s inputs to continue the simulations, or rollback-based where a player could predict the other player’s inputs, but rollback and resimulate if the predictions were incorrect. In contrast, in our current production of Infinite MR Arcade, we are building a mixed reality colocated physics sandbox using Unity. Unity’s physics engine is technically not fully deterministic, so the only way to get lockstep protocol to work is if we designed our own deterministic physics engine and simply use Unity (or any other popular alternatives like Unreal or Godot) as a rendering engine.
Even then, lockstep as a concept is fairly incompatible with XR requirements. Lockstep with rollback works really well for Fighting and RTS genres, because input types are fairly simple key presses along with basic joystick axes. It’s easy to make predictions if all we have to worry about is if the other player is holding onto a button, or simply staying idle. In XR, not only do we have button inputs and joystick axes, we also have 3D controller poses (position and rotation) as well as IMU measurements such as angular velocity and linear acceleration. More importantly, in the former, fairness matters way more than smooth experience. So not only does the potential limitations of lockstep protocol simply not even matter for Fighting and RTS, the input types they deal with make the simulations fast enough anyways. Lastly, although lockstep can be designed to work with any number of players, the number of players must be predetermined and every player must be online so that simulations can continue. That means that it is almost (but probably not certainly) impossible to add and remove players during the middle of a game. Scalability with lockstep is such a huge crutch in adapting it for XR experiences, but it’s still a very interesting and viable line of thought for developing a colocated XR experience.
Okay, finally, what about client authoritative models? Social games like RecRoom and VRChat all use a client authority heavy design with central relay as its infrastructure. Even though I made NGO and Photon sound exclusively like a server authoritative framework (and they primarily are), both support client authority models with fluid ownership exchange. When a client “owns” a network object, they are the ones responsible for locally simulating the object and reporting the state changes (could be absolute or deltas) to a relay or authoritative server, which would then broadcast the changes to the rest of the players. In many cases where latency is an issue, client authoritative models can be a great way to give the illusion of instantaneity, but the latency doesn’t just magically disappear. While one player owns an object and sees it as if they can affect it in real time, other players would still feel the latency.
Although that is acceptable for a social hangout type of games – and with careful designs, even fast-paced real-time gameplays could be made possible – it still doesn’t solve the issue of authority transfer logic. Within well-defined scopes such as real-time 1v1 matches or turn-based table top games, it is possible to lay out exactly when ownership over objects have to be transferred among the players. However, for a physics sandbox with an undefined number of players, that becomes a little tricky. Let’s say that there are three players in a session, two of them are playing table tennis, and the third is simply observing them. In a strictly 1v1 session, with players strictly identified as players or observers, if one player serves or returns another player’s serve or hit, they can notify or initiate a transfer of ownership. The server would know to transfer the authority to the other player and not any of the observer(s). Observers simply have to update the ball and paddle poses as they come in from a central relay.
In a sandbox context, however, where everyone can interact with any object in the scene, even with a central authority server, it’d be impossible to tell who should own the ball as it flies off of some player’s paddle. Maybe you can encapsulate the client authority model within the larger server authoritative model by enforcing player signup prior to starting a match and accurately keeping track of who is playing what at any moment. That’s absolutely possible, and probably a very common and good enough solution for online VR social games with interactive mini games. However, for a local multiplayer with a significantly higher budget for bandwidth and latency, such a solution might be somewhat “reserved”, while ironically being less scalable for packing in as many interactive items as possible into a multiplayer sandbox.
Taming the Impossible
Now that we finally covered some background and motivations, I wish to provide just one of many concrete examples of how we made strictly server authoritative design viable with respect to latency. The core idea was a common sense “greedy approach”, which involved the following best effort steps:
- the client must send out controller updates as soon as it is available,
- the server must propagate the controller updates through some arbitrary chain of updates as soon as it receives it,
- the server must send out the resulting game state (which reflects the client controller update) immediately,
- and finally the client must receive the new game state as soon as possible and immediately render it.
As sound as that idea was, the first time I had a working implementation I was observing around 30-40 ms of total latency. It was good enough for placing decorative objects around the scene and throwing some darts with no considerable jitters, so I didn’t give it much thought initially. However, with the addition of reflex based items like table tennis and air hockey, we noticed that such level of latency was bordering on unplayable. In an age when online game services are providing sub 20-40ms of ping (although I’ll never know how they’re actually calculating those metrics), 30-40 ms latency over LAN, even wirelessly, seemed way over what is theoretically and practically achievable. At this point, we knew that we had to establish a tangible model of what even is that theoretical limit, and how we’d work our way towards it.
After quite a significant effort invested into R&D while simultaneously working on game contents, we’ve finally arrived at a concrete model as illustrated by Figure 2 and Figure 3. I included two diagrams to show that the model is generalizable to any ratio between average network RTT and fixed delta time. First, we must cover some of the assumptions in this model.
- Network round-trip time (RTT) will be a fixed average with a one-way trip being precisely half of RTT.
- There is no additional delay besides the RTT.
- Tick interval will be a fixed delta time representing fixed physics and render update. Normally in Unity, fixed update runs at a different frequency than the render update loop (the default Update/LateUpdate) and fixed update is mechanistically driven by the update loop, but for the sake of simplicity we will assume a unified clock.
- Server and client clocks are not guaranteed to be in any sort of sync, which leads to some interesting properties that will be the core focus of this discussion.
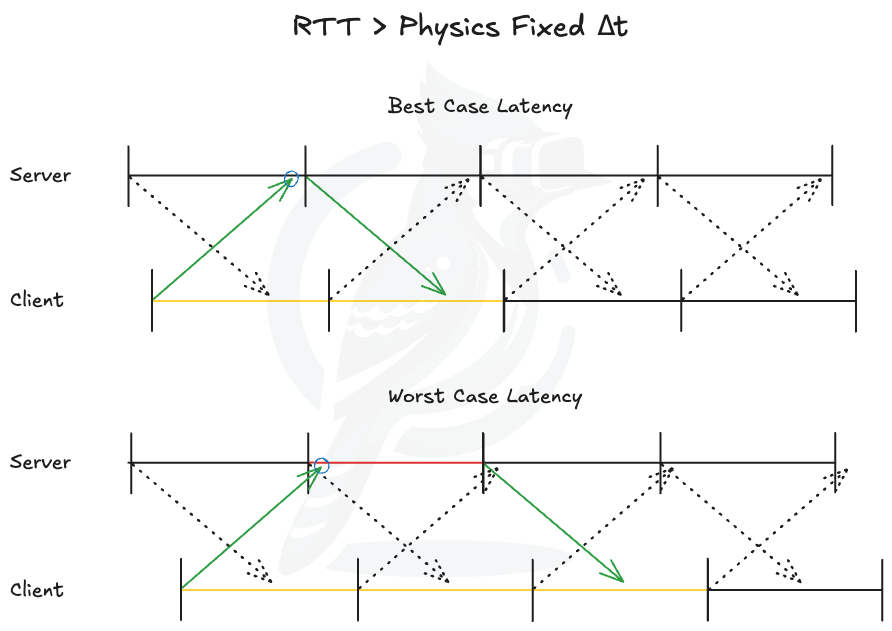
Figure 2. RTT > Physics Fixed Delta Time
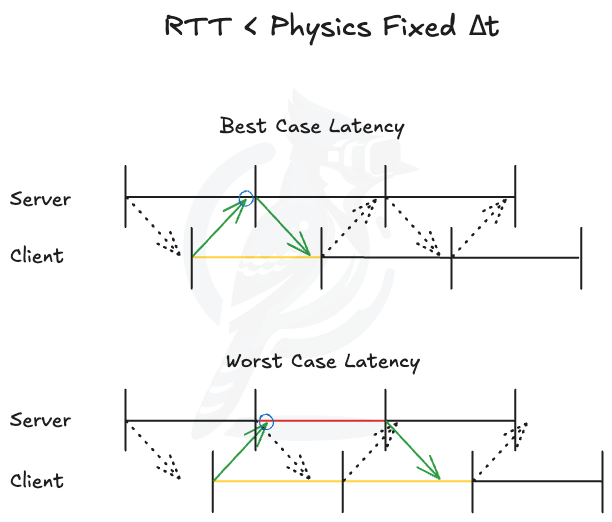
Figure 3. RTT < Physics Fixed Delta Time
Through these assumptions, we have an emergence of what could be called the best and worst case total latencies, and the two extremes set an expected range of total latency in our server authoritative system. This variance comes directly from our third assumption that we can’t predict nor reliably control the clock synchronization between a server and a client without some external mediator. Thus, a client’s message can land anywhere between a server’s fixed update ticks, which are the only discrete opportunities to send out game state updates. And on a closer inspection, we can discern two distinct properties. First is that if the client’s message is received just before a server’s tick, it will result in the best-case latency because a game state affected by the client’s update is sent out as quickly as possible. On the other hand, if the client’s message is received just after a server has executed a tick, it will result in the worst case latency, simply because it’d have to wait approximately a whole tick before the next network update opportunity.
Next we want to see if those two properties hold mathematically. We can treat the clock as a discontinuous function, with each fixed update tick corresponding to a discontinuity. Between two successive ticks, the latency varies continuously: as the arrival time moves from immediately after the left tick toward the right tick, the waiting time until the next update decreases monotonically from its maximum down to its minimum. There are two symmetric extreme cases, arrival just after the left tick or just before the right tick, so without loss of generality we assume the message arrives just after the left tick. As the arrival point moves rightward, the latency decreases monotonically to the best-case latency at the right tick. Therefore any message arriving between the ticks has latency lying between these two extremes.
Finally we want to derive the formulas to determine the best and worst case total latencies. Because the best-case latency is one where the gap between the two one-way trips approaches zero, and the client still needs to wait for its own fixed update to render the server reported game state, it can be approximated by rounding up the RTT to the nearest multiple of delta time:
Lbest ≈ ⌈RTT/Δt⌉⋅Δt
On the other hand, since the worst-case latency is delayed at most a single frame:
Lworst ≈ Lbest + Δt
As simple as that! But now let’s see how powerful this simple model can be.
Let’s assume we’re working with 120 FPS, which yields approximately 8.33 ms per frame, and suppose we had an average RTT of 10 ms. That means our lower and upper bounds according to our little formulas would be 16.67 ms to 25 ms. Previously I revealed that our first implementation of our networking stack yielded around 30-40 ms of latency. In our project, we used an even higher frame rate and measured an average RTT slightly lower than 10 ms (I must emphasize again that this is all wireless), which points to the fact that 30-40 ms of latency was severely over what was theoretically achievable.
Not only did this model tell us that there are definitive opportunities for optimizations, it also told us what was specifically in our control as software developers, not as embedded engineers or wireless protocol designers. Stepping through our assumptions, we can rule out two points, which are RTT and clock synchronization. Yes, clock synchronization can be achieved using something conceptually similar to an NTP server, but for a commercial game with diverse user demographics, that would be an unreasonable burden on the end-users. It would also require that the game engine maintain a strict temporal interval between fixed updates as well as extend the ability to shift or delay this update cycle to match the client’s clock against the server’s clock to achieve the best-case total latency given some average RTT. Even then, the inconsistent nature of RTT would lead to a catastrophic collapse of this approach.
However, there are two remaining factors that we can still control, which are update frequency and non-network sources of delays. Regarding update frequency, if we increase the tick rate, we decrease the delta time, thereby causing a downward shift of the minimal latency range. That’s a simple, obvious optimization, but the trade-off would be increased network packet transmission rate and increased chances of burst traffic. On the other hand, reducing non-network delays is a straightforward idea but requires heavy architectural decisions and meticulous planning. On one level, non-network delay can come from greater than expected amount of computation, but that’s generally in the hundreds of microseconds scales and maybe up to 1-2 milliseconds especially during Garbage Collection. Unless the codebase was written very poorly, this aspect of non-network delay is just a source of minor jitters, not a persistent increase in latency.
The true concern regarding non-network delays is delays occurring from interdependency. In XR, we are primarily interested in grab interactions where objects can be classified as grabbables or grabbers. By leveraging Separation of Concerns (SoC), we treat grabbables and grabbers as independent agents with their own responsibilities and reactions to environmental stimuli. This modularity enables flexible extensions such as permission rules, autonomous behaviors, and complex interaction patterns. However, the issue with this design is that if a grabber’s transform is updated and we don’t set up an explicit pipeline for a grabbable to respond to its grabber’s transform update, we’d have to wait until the next frame to see guaranteed changes to grabbables be reflected.
We bring up the term “guaranteed”, because by default Unity only provides FixedUpdate, Update or LateUpdate, and for something like grabbables and grabbers, we wish to use FixedUpdate to step through their state machines. However, because we have no way of guaranteeing the ordering of gameobjects’ fixed update methods, we cannot guarantee that a grabbable will execute its block of fixed update immediately after its grabber’s. Therefore, if we previously had 16.67-25 ms minimal total latency range, then due to grab interaction interdependency, we’d instead be looking at 25-33.33 ms.
To add insult to injury, we have two additional sources of inefficiency, each adding an extra delta time to the total latency, first being the client’s controller broadcast and the other the server’s game state broadcast. Because the client’s controller poses are updated by calling an API to the controllers’ hardware, whether it be through OpenXR or Meta SDK, and we don’t have explicit control over when these updates get called except for the case where Meta SDK let’s us have the controllers update on FixedUpdate, we lack the ability to have client controller broadcast immediately follow a controller update leading to an additional delay by a frame. Similarly, because a server’s game state broadcast is also run on FixedUpdate, by the same pattern, we get another frame of delay. All in all, that’s a 41.67-50 ms minimal latency range! That explains why our initial implementation had very high latency.
So how do we fix this? Well, regarding grab interaction, the standard approach seems to be to have a grabbable subscribe to a grabber “OnGrab” so that the grabber can explicitly update the grabbable’s transform. At first I thought this might be bordering on tight coupling, but for a long chain of interactions where each entity can simultaneously have a grabbable and a grabber, the standard approach seems to be a fairly strong solution, although we’d have to watch out for cycles. We could also take this approach to client controller broadcast by subclassing OVRCameraRig and overriding its FixedUpdate.
Unfortunately, for server game state broadcast, we need a different solution, because a game state broadcast should only be made when all objects have been properly updated and the physics simulation has run. So even if we somehow hacked together a way to have the last updated object invoke the broadcast, that can only happen before a physics simulation is actually run. So in order to be able to send a broadcast immediately after physics simulation, there’s no way around having to inject a new update block following a physics fixed update by using Unity’s relatively new low-level API. Since in our Infinite MR Arcade we don’t really have too crazy of interactions and we have to add a new playerloop anyway, I decided to just kill three birds with one stone, by coordinating fixed updates using PlayerLoop, which is illustrated by Figure 4.
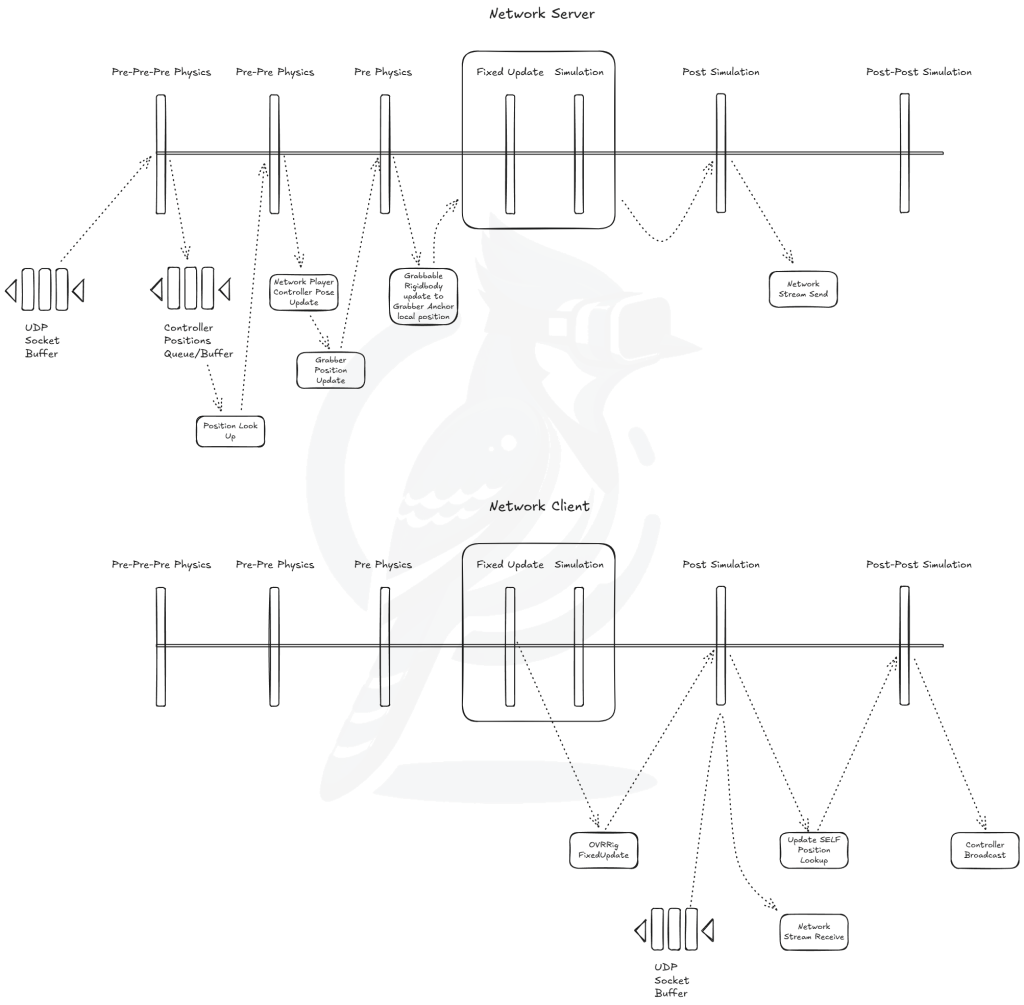
Figure 4.
And after making all these adjustments, we were able to achieve a measured total latency between 9-13 ms! You can see this for yourself by trying out the colocated mode on our Infinite MR Arcade. Just be aware that as of patch 1.2.8, we have interpolation on decorative objects (not on shapes yet), so there will be slightly higher latency on them, but we also have a tailor fitted interpolation technique to keep the latency nearly true to minimal latency.
As I have just hinted, there are many more techniques involved in bringing out realism in a colocated experience. In this article, we have not yet covered interpolation or dealing with burst traffic in general. We also haven’t covered how to create a bidirectional, low-latency, high-throughput, and reliable RPC system, which sounds ridiculous but can be achieved in local networks due to increased bandwidth budget. Based on how much time I have outside of active development and maintenance, I’m hoping to write articles on those topics as well.
Jay Oh – 09/14/2025

Leave a comment